

C/C++를 포함한 거의 대부분의 언어에서는 부동소수점의 제곱근 함수를 지원하고 있다.
그리고, 정수 범위에서 제곱근을 구할 때는 보통 이 제곱근 함수를 활용하여 간단히 구현한다.
그런데, 순수하게 정수 범위에서 동작하는 제곱근 함수가 있다면 조금은 더 빠르게 동작할 것 같다.
파이썬의 경우 아예 이러한 함수를 stdlib에서 지원한다.
정수 범위에서 제곱근을 구하는 아이디어에는 몇 가지 방식이 있다.
unsigned ISqrtByNewton32(const unsigned n)
{
unsigned x = n;
unsigned y = (x + 1) / 2;
while (y < x) {
x = y;
y = (x + n / x) / 2;
}
return x;
}
def improved_i_sqrt(n):
assert n >= 0
if n == 0:
return 0
i = n.bit_length() >> 1 # i = floor( (1 + floor(log_2(n))) / 2 )
m = 1 << i # m = 2^i
#
# Fact: (2^(i + 1))^2 > n, so m has at least as many bits
# as the floor of the square root of n.
#
# Proof: (2^(i+1))^2 = 2^(2i + 2) >= 2^(floor(log_2(n)) + 2)
# >= 2^(ceil(log_2(n) + 1) >= 2^(log_2(n) + 1) > 2^(log_2(n)) = n. QED.
#
while (m << i) > n: # (m<<i) = m*(2^i) = m*m
m >>= 1
i -= 1
d = n - (m << i) # d = n-m^2
for k in xrange(i-1, -1, -1):
j = 1 << k
new_diff = d - (((m<<1) | j) << k) # n-(m+2^k)^2 = n-m^2-2*m*2^k-2^(2k)
if new_diff >= 0:
d = new_diff
m |= j
return m
미리 제곱수를 계산해놓은 뒤 이진 탐색 아이디어를 적용하는 방법도 있다. (관련 사이트)
SSE가 탑재된 CPU에서는 _mm_sqrt_ss() 함수를 활용해서 더 빠른 연산을 수행할 수 있다.
float에서 처리되지만, 엄청난 성능을 보여준다.
int ISqrtByIntrinsic32(const int n) noexcept
{
register __m128 xmm0 = _mm_setzero_ps();
xmm0 = _mm_cvt_si2ss(xmm0, n);
xmm0 = _mm_sqrt_ss(xmm0);
return _mm_cvtt_ss2si(xmm0);
}
이 외에도 중학교에선가 수학시간에 배웠던 손으로 계산하는 방법을 적용하는 알고리즘도 있다. (관련 사이트)
여러가지 정수 제곱근 알고리즘을 int16_t 및 int32_t 용으로 구현해서 100만번씩 실행해 성능을 비교해봤다.
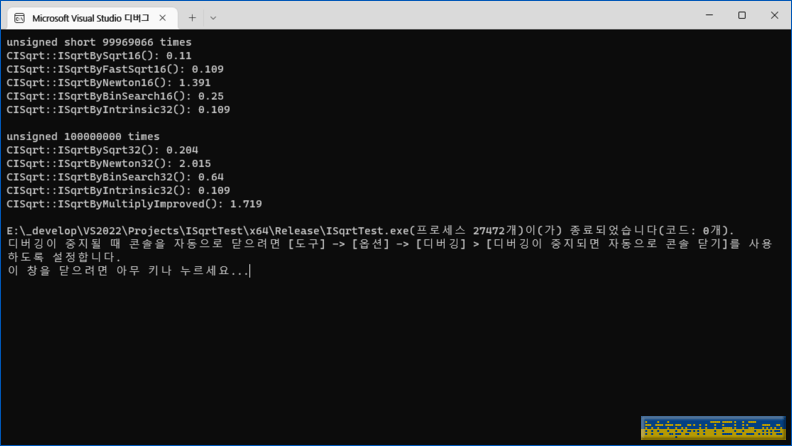
놀랍게도 그냥 sqrt() 함수를 실행시켜 정수형으로 형변환한 것이 거의 가장 빨랐다.
Intrinsic 함수를 사용하는 쪽이 조금 더 빠르긴 했지만, 굳이 별도의 알고리즘을 적용할 필요는 사실상 없는 것 같다.
unsigned short 99969066 times CISqrt::ISqrtBySqrt16(): 0.11 CISqrt::ISqrtByFastSqrt16(): 0.109 CISqrt::ISqrtByNewton16(): 1.391 CISqrt::ISqrtByBinSearch16(): 0.25 CISqrt::ISqrtByIntrinsic32(): 0.109 unsigned 100000000 times CISqrt::ISqrtBySqrt32(): 0.204 CISqrt::ISqrtByNewton32(): 2.015 CISqrt::ISqrtByBinSearch32(): 0.64 CISqrt::ISqrtByIntrinsic32(): 0.109 CISqrt::ISqrtByMultiplyImproved(): 1.719
이게 뭔 일일가 싶어 디스어셈블 해보니 이유를 할 수 있었다.
컴파일러가 알아서 AVX 명령어로 컴파일하기 때문[각주:1]이었다.
00007FF6FA381AA0 mov ecx,ebx 00007FF6FA381AA2 vxorps xmm1,xmm1,xmm1 00007FF6FA381AA6 vcvtsi2sd xmm1,xmm1,rcx 00007FF6FA381AAB vxorpd xmm0,xmm0,xmm0 00007FF6FA381AAF vucomisd xmm0,xmm1 00007FF6FA381AB3 ja main+93Bh (07FF6FA381ABBh) 00007FF6FA381AB5 vsqrtsd xmm0,xmm1,xmm1 00007FF6FA381AB9 jmp main+944h (07FF6FA381AC4h)
복잡한 생각 필요 없고 그냥 sqrt() 사용하자
| memcpy() 최적화 2차 도전 (0) | 2023.10.23 |
|---|---|
| 주의해서 사용해야 하는 파이썬 Numpy 배열의 메모리 내 저장 순서 (0) | 2023.08.09 |
| 자신보다 크거나 같은 최소의 2의 제곱수는? (1) | 2022.09.18 |
| CMap vs std::map (4) | 2022.09.13 |
| Visual C++에서 Epoch time 계산하기 (0) | 2022.08.28 |
