

깃헙 zlib-ng 라이브러리에 아래와 같은 내용이 반영된 수정이 올라왔다.
unaligned access를 허용하지 않는 환경에서는 memcpy(), memcmp()를 사용하고, 허용된다면 직접 비교한다는 것.
/* Force compiler to emit unaligned memory accesses if unaligned access is supported
on the architecture, otherwise don't assume unaligned access is supported. Older
compilers don't optimize memcpy and memcmp calls to unaligned access instructions
when it is supported on the architecture resulting in significant performance impact.
Newer compilers might optimize memcpy but not all optimize memcmp for all integer types. */
#ifdef UNALIGNED_OK
# define zmemcpy_2(dest, src) (*((uint16_t *)(dest)) = *((uint16_t *)(src)))
# define zmemcmp_2(str1, str2) (*((uint16_t *)(str1)) != *((uint16_t *)(str2)))
# define zmemcpy_4(dest, src) (*((uint32_t *)(dest)) = *((uint32_t *)(src)))
# define zmemcmp_4(str1, str2) (*((uint32_t *)(str1)) != *((uint32_t *)(str2)))
# if UINTPTR_MAX == UINT64_MAX
# define zmemcpy_8(dest, src) (*((uint64_t *)(dest)) = *((uint64_t *)(src)))
# define zmemcmp_8(str1, str2) (*((uint64_t *)(str1)) != *((uint64_t *)(str2)))
# else
# define zmemcpy_8(dest, src) (((uint32_t *)(dest))[0] = ((uint32_t *)(src))[0], \
((uint32_t *)(dest))[1] = ((uint32_t *)(src))[1])
# define zmemcmp_8(str1, str2) (((uint32_t *)(str1))[0] != ((uint32_t *)(str2))[0] || \
((uint32_t *)(str1))[1] != ((uint32_t *)(str2))[1])
# endif
#else
# define zmemcpy_2(dest, src) memcpy(dest, src, 2)
# define zmemcmp_2(str1, str2) memcmp(str1, str2, 2)
# define zmemcpy_4(dest, src) memcpy(dest, src, 4)
# define zmemcmp_4(str1, str2) memcmp(str1, str2, 4)
# define zmemcpy_8(dest, src) memcpy(dest, src, 8)
# define zmemcmp_8(str1, str2) memcmp(str1, str2, 8)
#endif
#endif
그런데, unaligned access를 지원하는 x86/x64 계열[각주:1]에서 최신 컴파일러를 사용하면 저런 처리는 알아서 다 해준다.
아래의 코드를 보자.
const static size_t SZ = 1000000000;
BYTE *p1 = new BYTE[SZ];
memset(p1, 0x7f, SZ);
BYTE* p2 = new BYTE[SZ];
for (size_t i = 0; i < SZ; i += 4) {
memmove(p2 + i, p1 + i, 4);
}
for (size_t i = 0; i < SZ; i += 4) {
*(uint32_t*)(p2 + i) = *(uint32_t*)(p1 + i);
}
memcpy() 또는 memmove() 한 방으로 끝날 것을 굳이 복잡하게 작성한 코드다.
그리고, 루프를 돌면서 memcpy()도 아니고 미묘하게라도 더 느린 memmove()를 사용해서 구현했다.
비주얼 스튜디오 2022로 디버그 모드에서 이를 컴파일한 결과는 아래와 같다.
우선 memmove() 파트를 보면 코드 그대로 부지런하게 memmove()를 호출하는 것을 볼 수 있다.

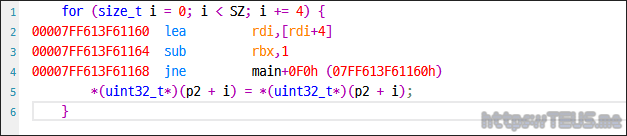
다음은 나름 최적화한 uint32_t*로 캐스팅해서 복사한 파트를 보자.
for() 루프는 동일하지만 맨 마지막에 call memmove() 대신 move dword ptr로 복사하는 것을 볼 수 있다.

당연하게도 memmove()를 사용하지 않는 쪽이 훨씬 더 빠르다.
그렇다면 이를 릴리즈 모드로 컴파일한 결과는 어떨까?
아래 컴파일 된 결과를 보자.
call memmove()는 사용하지 않고, for() 루프와 합쳐서 코드를 생성하는 것을 볼 수 있다.

따라서, 나름 최적화한(?) 아래쪽과 100% 동일한 코드를 생성한다.

하는 김에 아래와 같이 p1를 p2로 바꿔서 무의미한 코드로 바꿔보면 어떨까?
for (size_t i = 0; i < SZ; i += 4) {
memmove(p2 + i, p2 + i, 4);
}
for (size_t i = 0; i < SZ; i += 4) {
*(uint32_t*)(p2 + i) = *(uint32_t*)(p2 + i);
}
memmove() 행은 코드를 아예 생성하지도 않는다.
그냥 무의미하게 루프만 돌려줌.

나름 최적화한 쪽도 마찬가지.
역시 무의미하게 루프만 돌려준다.
memset()에 대해서도 비슷한 포스팅을 했었는데, 최신 환경에서 최신 컴파일러들은 이런 최적화는 알아서 해준다.
한줄 요약: 컴파일러가 다 알아서 해주니 memmove() 편하게 쓰자
덧1. 원론적으로 memcpy()는 메모리 영역이 충돌하는지 확인하지 않고, memmove()는 확인한다.
따라서 미세하게라도 memcpy()가 더 빠르지만, memmove()가 훨씬 안전함.
덧2. 이 글은 zlib-ng의 구현이 틀렸다는 얘기가 아님. 모든 환경을 지원하려면 저렇게 작성해야 함.
덧3. 루프 내에 코드가 없어도 for() 루프 문은 컴파일 되는데, 다양한 이유에서 미묘한 delay가 필요하기 때문.
| Visual C++에서 Epoch time 계산하기 (0) | 2022.08.28 |
|---|---|
| Visual C++의 rand()에 대체 무슨 일이 있는 거냐? (2) | 2022.05.19 |
| 조건에 맞는 기약분수의 갯수 (0) | 2021.08.22 |
| 최대공약수(GCD)를 구하는 가장 빠른 방법은? (0) | 2021.08.22 |
| n/φ(n)이 최소가 되며 두 값이 순열관계인 천만 이하의 n은? (0) | 2021.07.14 |
